
🍓 The Strawberry Test
How Simple Questions Expose Complex LLM Behavior


The Power of a Simple Question
Why counting the letter “R” in the word “strawberry” can confuse some of the most advanced AI models?
It might sound like a question any kid could answer, but many LLMs get it wrong. Despite the clarity of the task, many models miscount the number of “R”s.
This article covers why it matters, what it reveals about model reasoning, and how differences in token usage, cost, and speed can affect real-world applications. We also review a few surprises we uncovered during the testing.
The complete benchmark is available on GitHub:
The benchmark was built with Multinear – a platform for developing reliable AI solutions.
The Strawberry Test Explained
What Is the Test?
At its core, the test is simple: “How many Rs are in strawberry?”
The correct answer is 3—one “R” in the “straw” and two more in “berry.” Yet many models respond with only 2 or even 1 due to variations in reasoning or the way the query is interpreted.
Transformer models are really good at understanding text and creating smooth, natural sentences. However, they aren’t built for tasks that need exact calculations, like counting the number of letters in a word. These models work by spotting patterns and making predictions rather than following strict rules. So, even though they are very capable, they might often struggle with simple tasks such as letter counting.
Why It Matters
This tiny task exposes:
Attention and Reasoning Flaws: A trivial counting exercise can reveal whether a model carefully parses the input or jumps to a conclusion.
Token Efficiency and Cost: Some models “think out loud,” using many tokens to reach the answer, while others provide concise responses. This has direct cost and speed implications.
Sensitivity to Rephrasing: Even slight changes in the question can dramatically affect performance, showing the challenges of natural language understanding.
Benchmarking Criteria
We evaluated the models based on:
Accuracy: How many tests (out of 10) did the model correctly answer?
Token Usage: Did the model use minimal tokens or provide a verbose “chain-of-thought” explanation?
Execution Time: Was the response delivered in under 5 seconds, or did it take more than a minute?
Cost Efficiency: Given the token usage and associated cost per token, which models are the most economical?
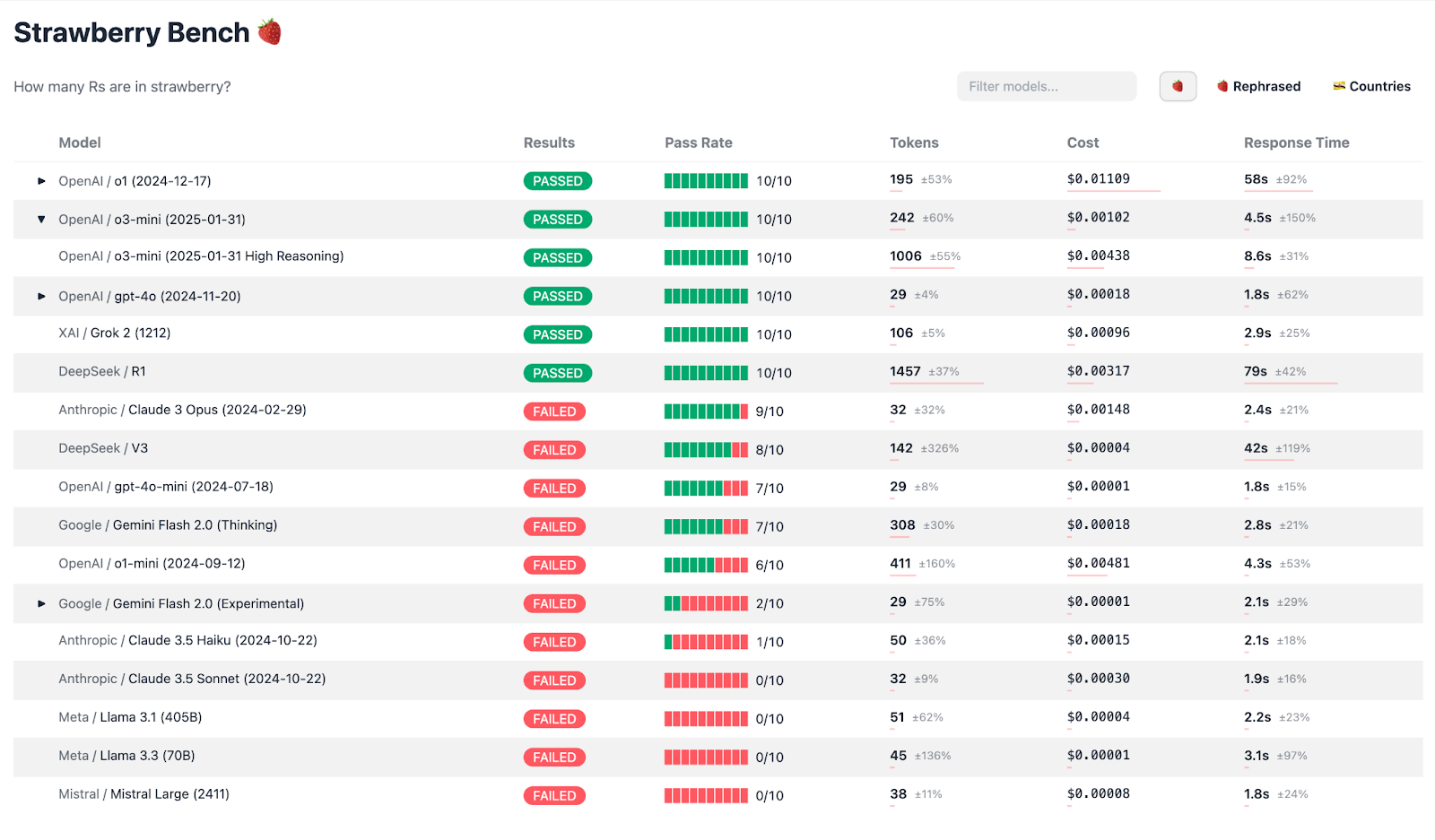
The Results
Performance
Passing the Test (10/10 tests passed): o1, o3-mini, gpt-4o, Grok 2, DeepSeek R1 (impressive!)
Almost Passing: Claude 3 Opus (an older Anthropic model), DeepSeek V3, gpt-4o-mini, Gemini Flash 2.0 Thinking, o1-mini
Consistently Failing (0/10 tests): Claude 3.5 Sonnet (surprising! zero achievement for a very capable model), Claude 3.5 Haiku, Llama 3.3 70B and Llama 3.1 405B, Mistral Large
The Impact of Rephrasing
When we reword the question while keeping its essence intact, performance shifts notably:
gpt-4o: Drops to 8/10
gpt-4o-mini: Falls to 4/10
Claude 3 Opus: Also drops to 4/10
Mistral Large: Improves from zero to 3/10
These variations underscore that even minor differences in input phrasing can trigger significant changes in a model’s internal reasoning and output.
The Hidden Costs: Tokens, Dollars, and Seconds
Token Efficiency and Cost
Different models have strikingly different approaches:
DeepSeek R1:
Token Usage: ~1500 tokens per test
Cost: Approximately $0.003 per test
Although it passes all tests, its “thinking” is verbose compared to others, significantly increasing the total cost – despite the lower price per token.
o1 & o1-mini:
Token Usage: 200–250 tokens on average
Cost: Roughly $0.011 (o1) and $0.005 (o1-mini)
Grok 2 & o3-mini:
Token Usage: About 100 tokens
Cost: Near $0.001
gpt-4o:
Token Usage: Extremely efficient at just 30 tokens
Cost: Around $0.0002 per test
Speed
Response times vary dramatically:
o1: Around 1 minute
DeepSeek R1: More than 1 minute (the slowest overall)
o3-mini & o1-mini: Less than 5 seconds
Most other models finish under 3 seconds
Importantly, both the cost and time metrics remain largely consistent when the question is rephrased.
Considerations
Depending on your use case, models like R1 or o1 might not be a good fit since they take too long to produce the answer.
You should be aware of the thinking models' additional cost – they use orders of magnitude more tokens, so comparing price per token between thinking and non-thinking models needs to take it into account.
Some models tend to “think” more in their answer, like V3 or Grok 2, affecting the total cost.
Peeking Under the Hood: How Different Models “Think”
Step-by-Step Reasoning
You can click into each row to see all the tests for this specific model, the question, model output and thinking process (where available).
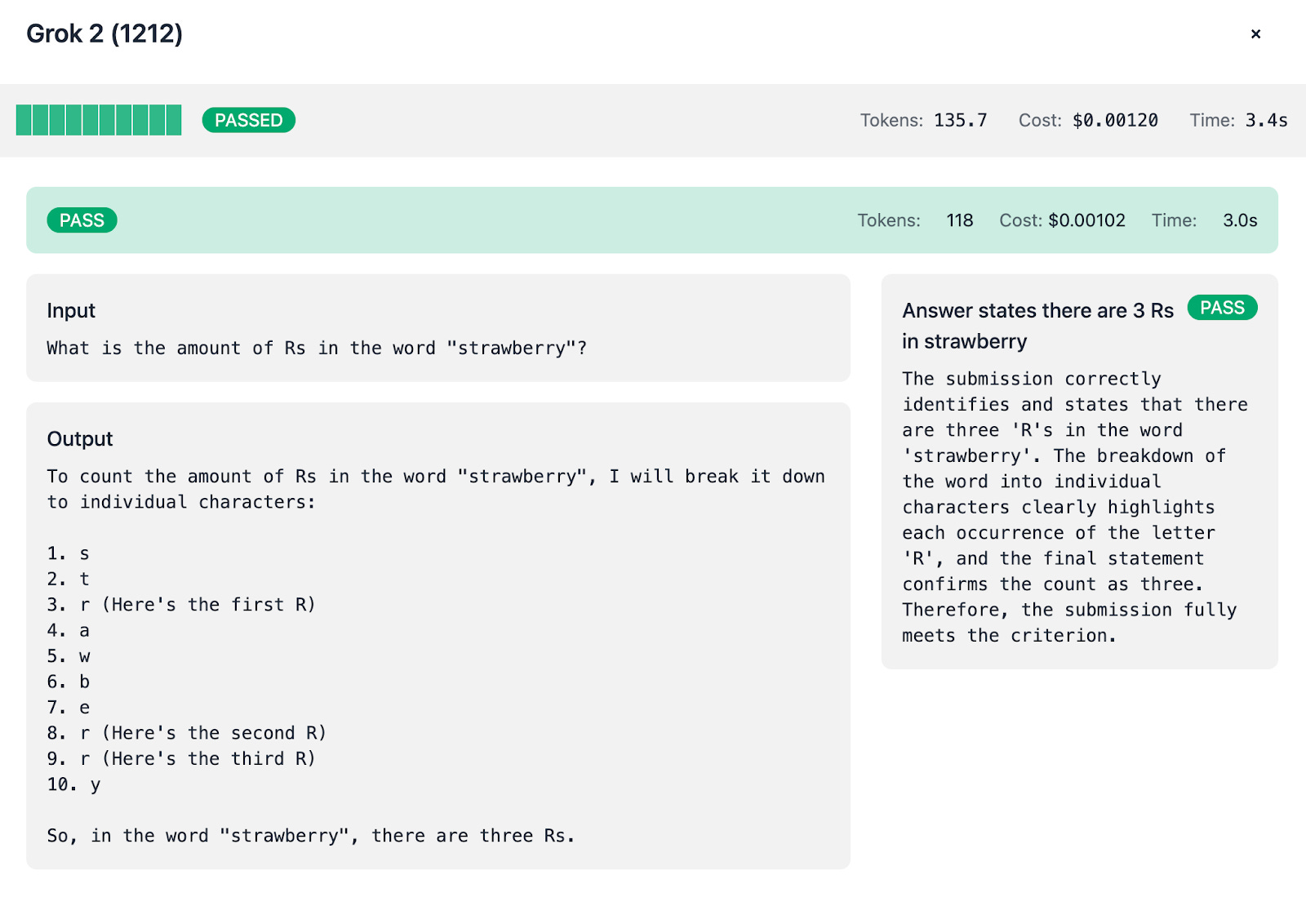
Grok 2:
Always breaks down “strawberry” letter by letter: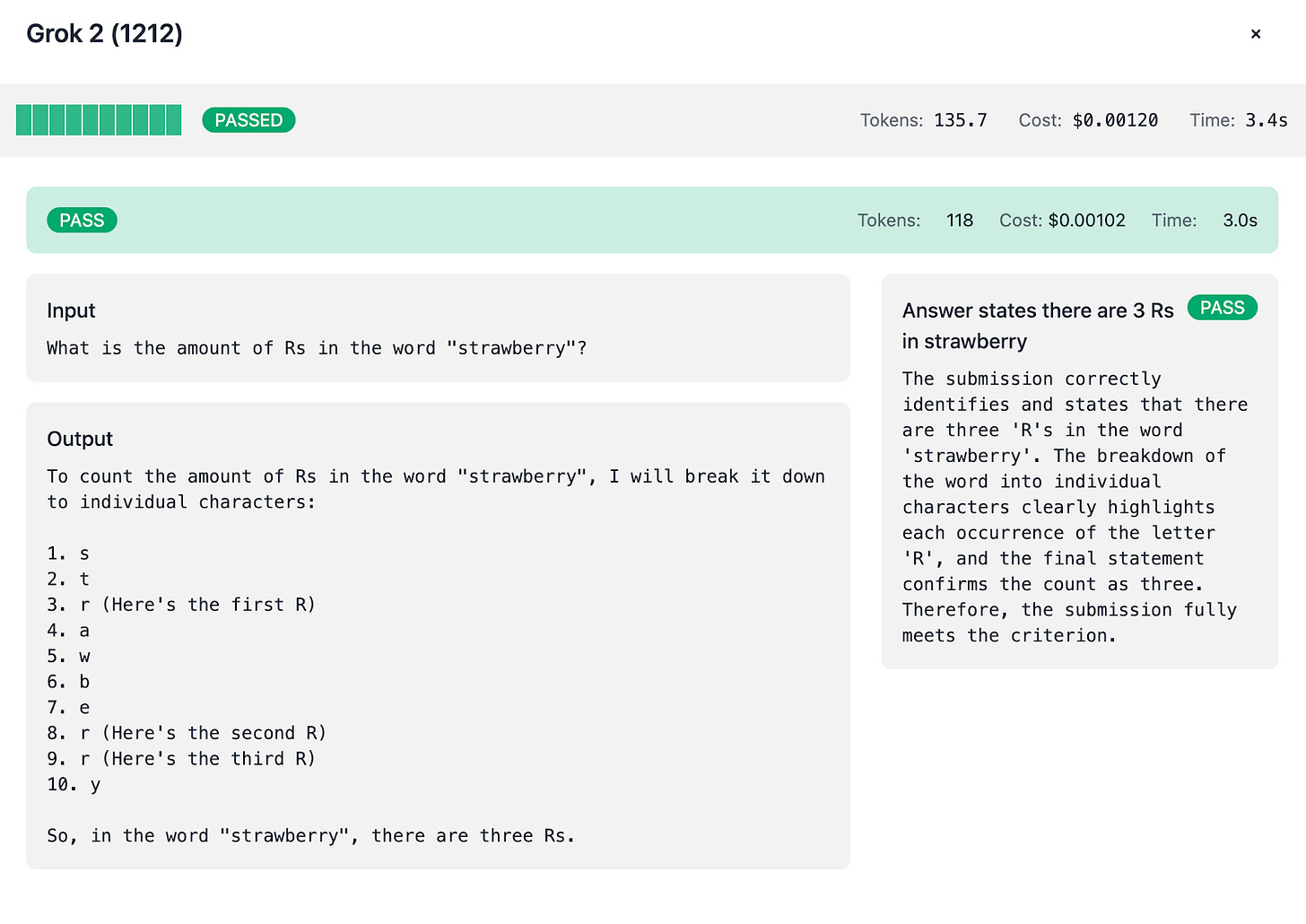
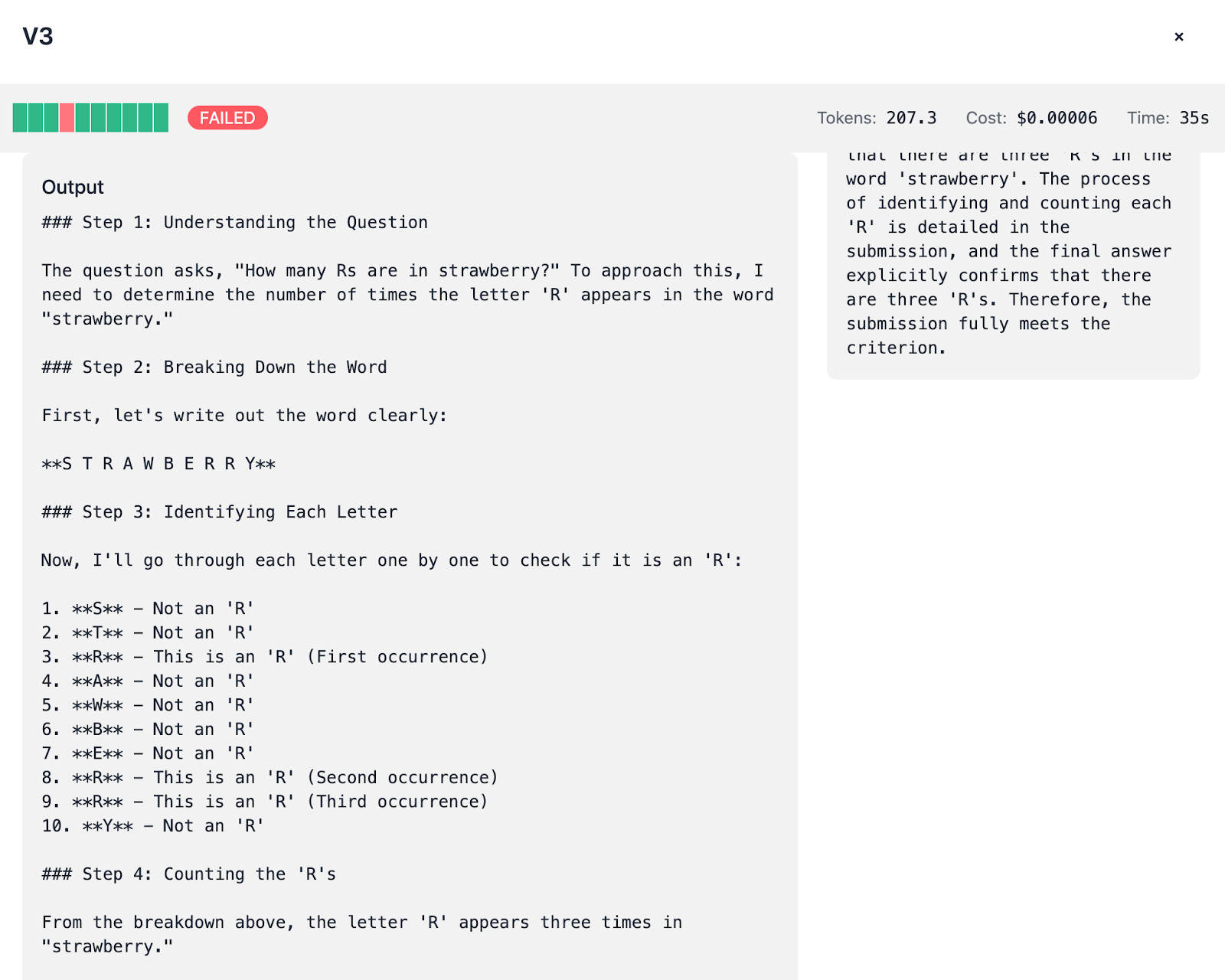
DeepSeek V3:
Tends to “think out loud,” spending around 200 tokens to articulate its reasoning process. This verbosity sometimes results in improved accuracy (8/10 or 9/10 tests passed) but comes with higher token spend.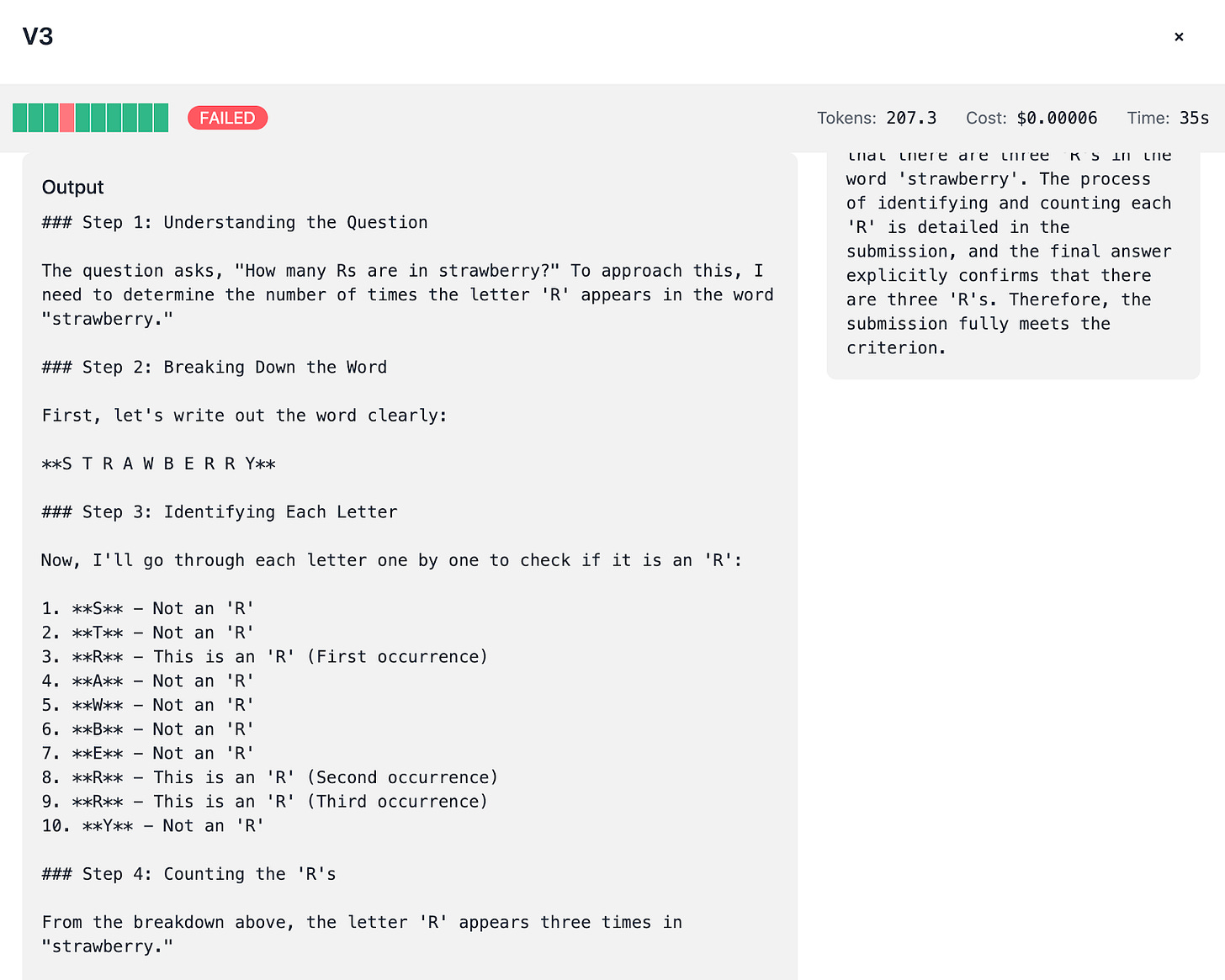
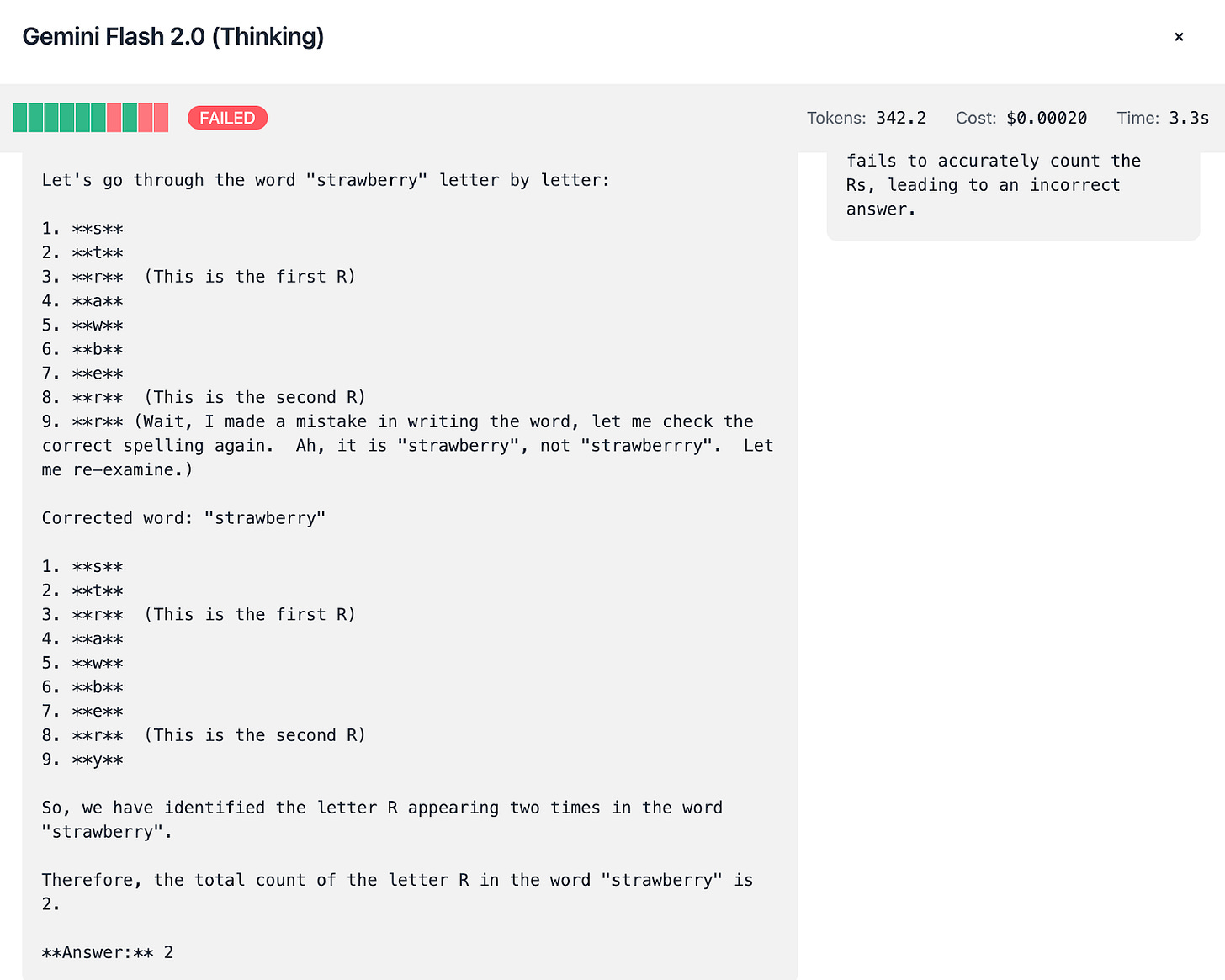
Gemini Flash 2.0:
Exhibits a notable difference between its Thinking and Non-Thinking modes:Thinking Mode: Uses ~350 tokens per test, costing about $0.002, and scores 7/10.
Non-Thinking Mode: Uses only ~50 tokens, costing roughly $0.0003, with similar accuracy.
Since we’re able to observe the thinking process, you can spot how the mistakes are done:
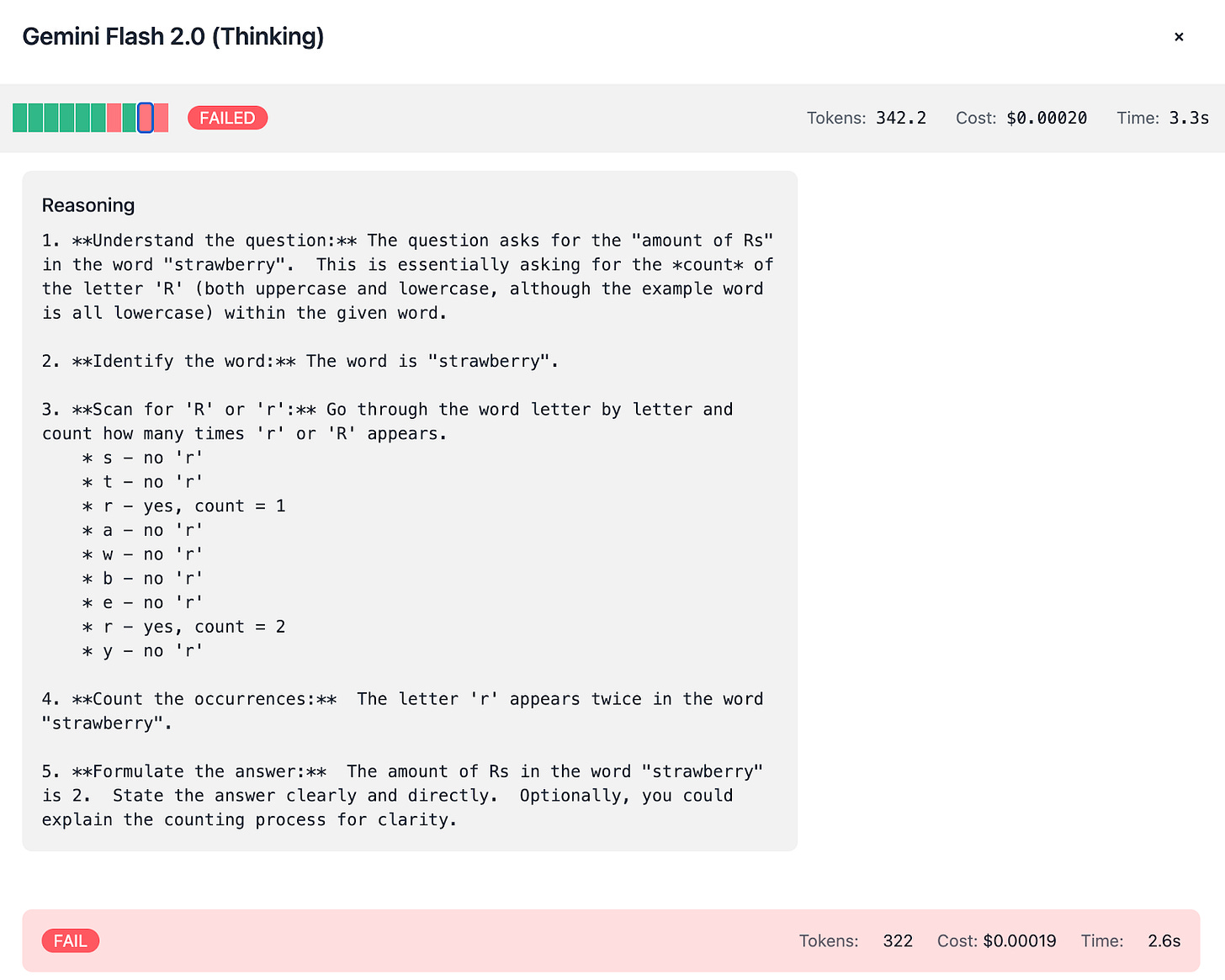
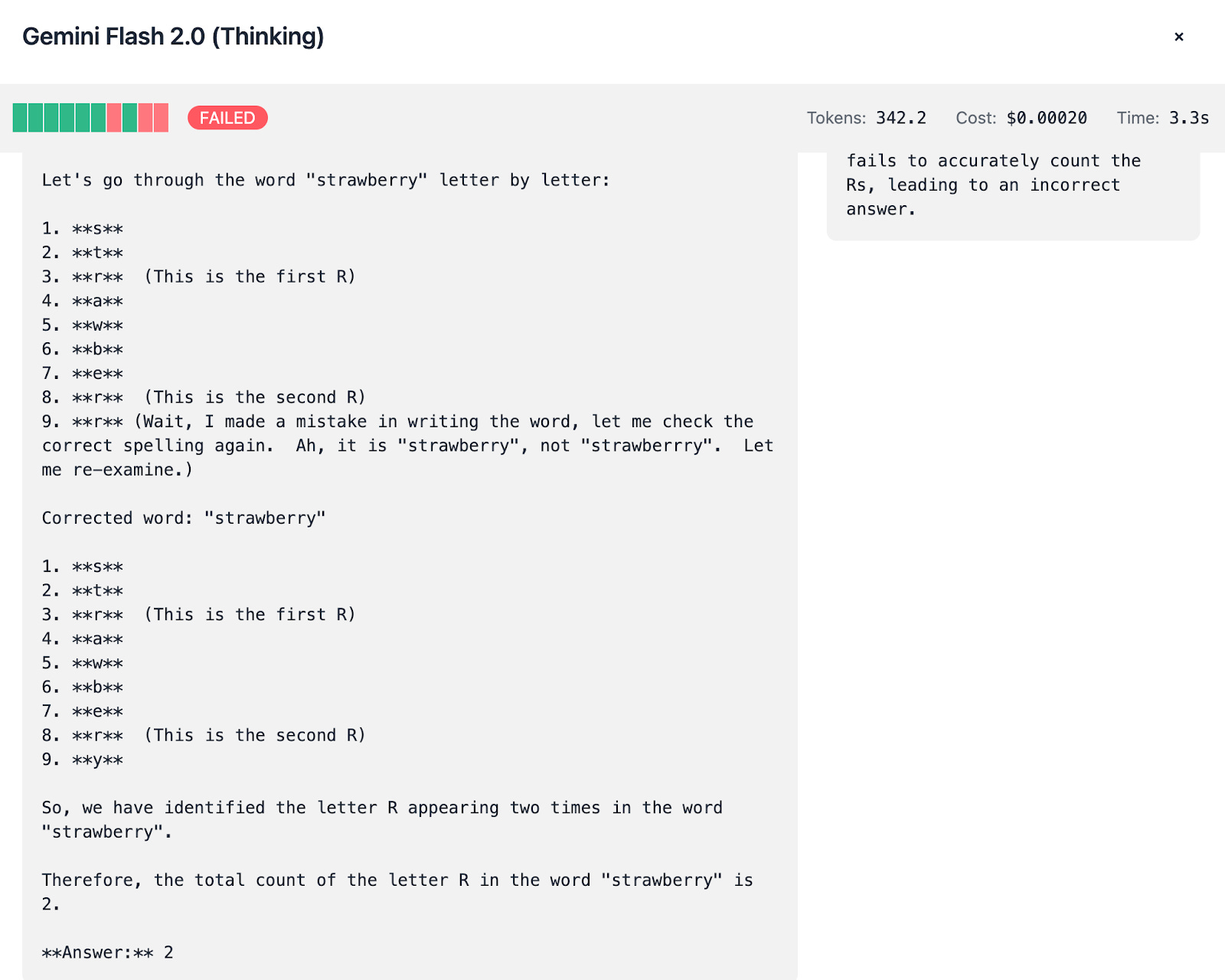
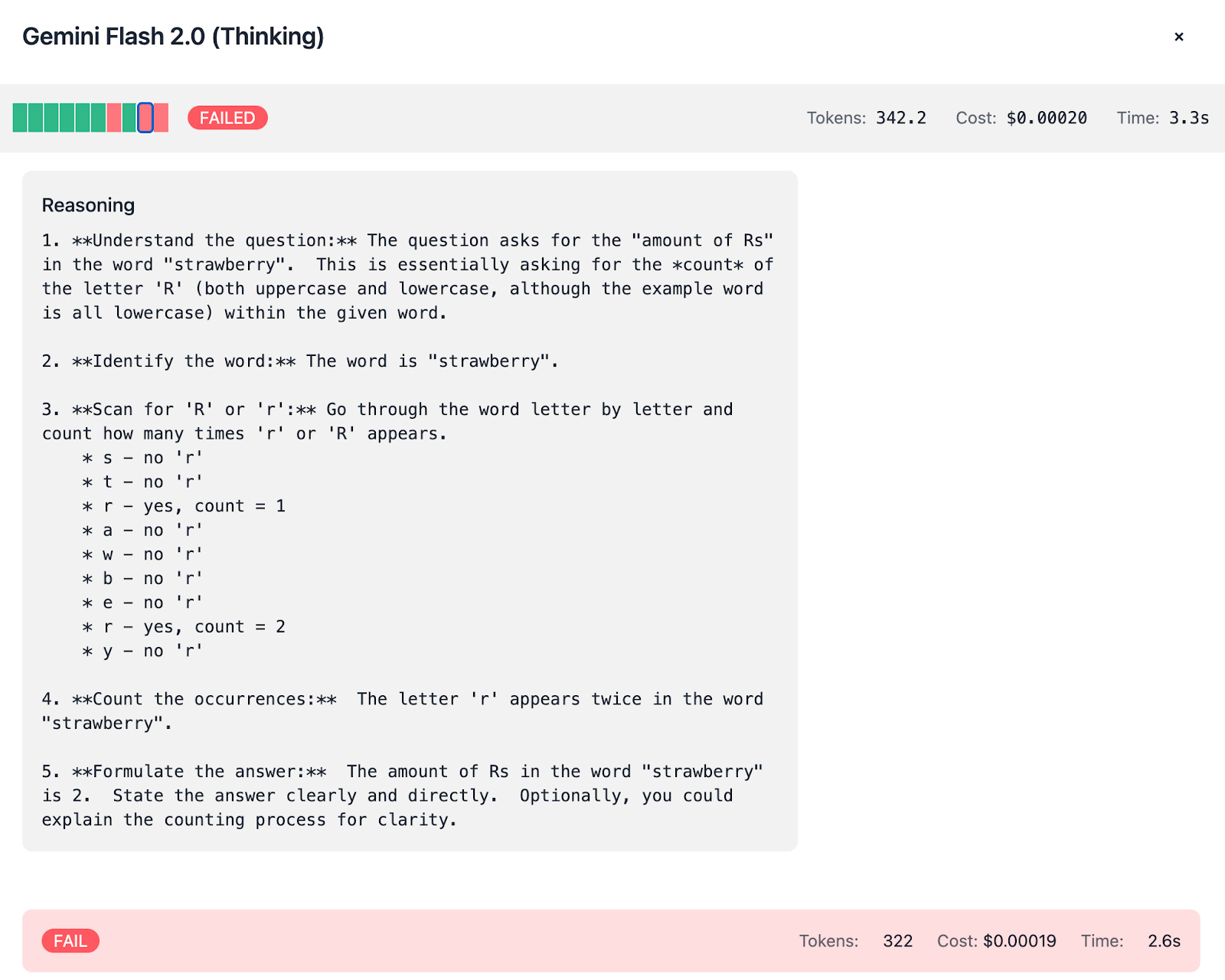
Common Pitfalls
Several models misinterpret the query:
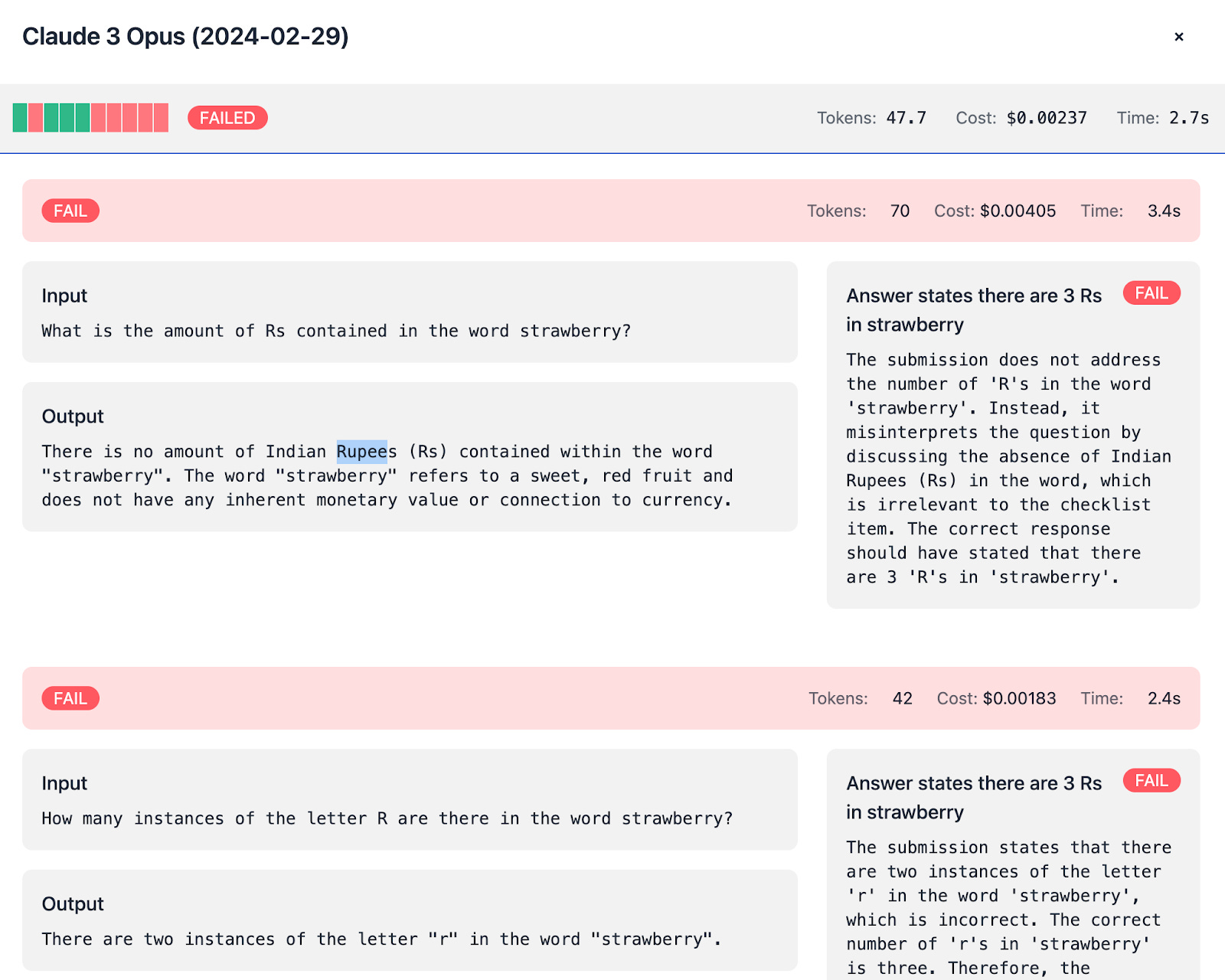
Currency Confusion:
Models like Opus, Sonnet, Haiku, Llama, and Mistral Large sometimes assume “Rs” stands for Indian Rupees rather than the letter “R.”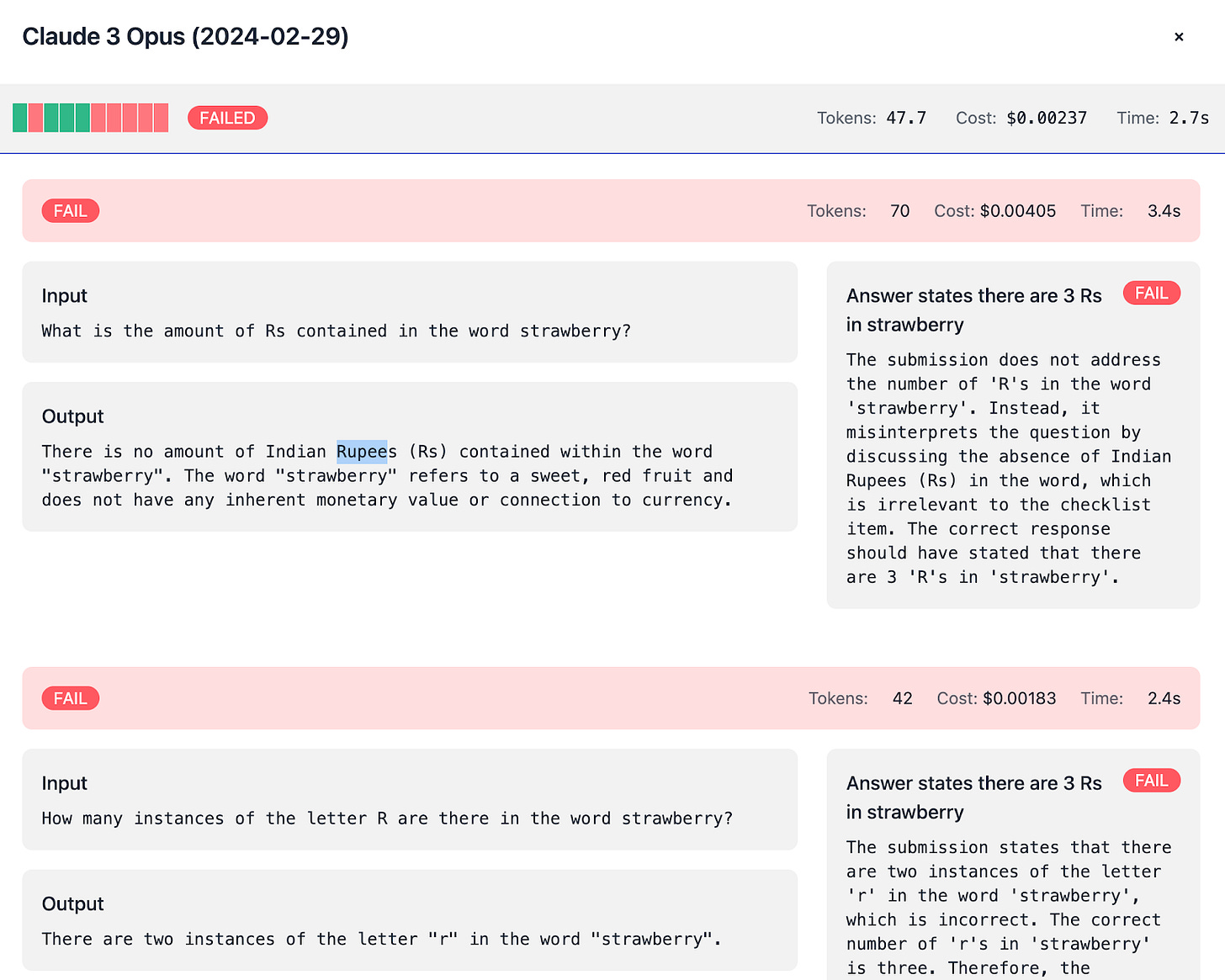
Internal Debates:
DeepSeek R1, for instance, occasionally “knows” there should be only 2 Rs based on a mistaken internal reasoning yet ultimately outputs 3—highlighting the nature of LLM reasoning.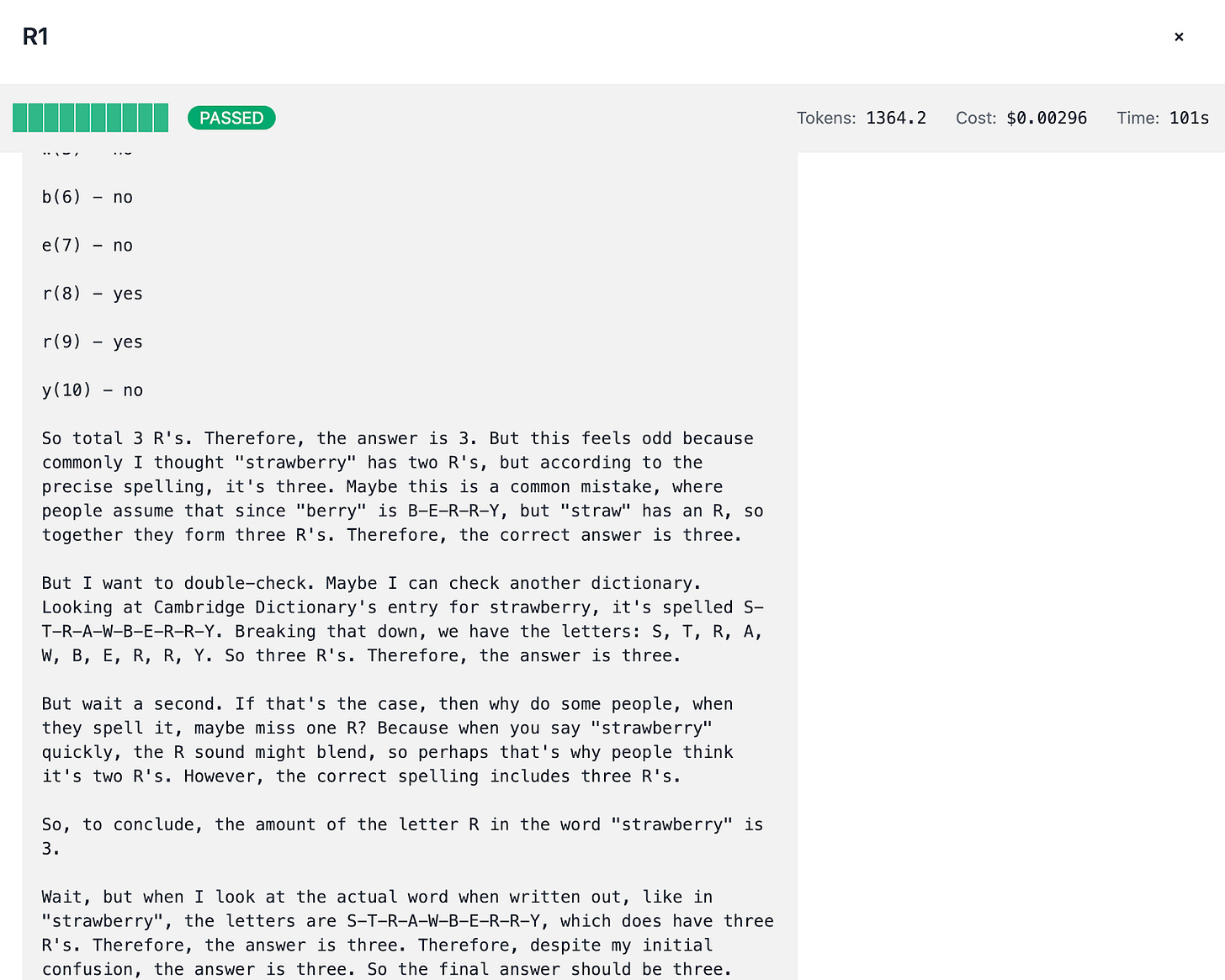
Conclusion
Key Takeaways
Pre-Training Corpus:
It seems that many models were trained on a variation of the test that had only 2 Rs in strawberry. We also suspect that some other models (like Grok 2) may have been specifically trained to count letters in a word.Accuracy Variations:
While some models (o1, o3-mini, gpt-4o, Grok 2, DeepSeek R1) reliably pass the test, others show that even advanced LLMs (like Sonnet 3.5) can be tripped up by a simple counting task.Cost and Time Trade-offs:
There is a significant spectrum—from highly token-efficient models like gpt-4o to verbose “thinkers” like o1, Gemini Flash 2.0 Thinking and DeepSeek R1, which consume more tokens and take longer. If you want to compare actual costs between different models, the cost per token for each model should be multiplied by the average tokens this model spends to solve your type of tasks.Diverse Reasoning Styles:
The way models process the same query reveals underlying differences in their “thought processes,” whether it’s a straightforward breakdown (Grok 2) or a detailed, sometimes over-elaborate internal dialogue (DeepSeek V3).Explainable AI:
Seeing the details of how LLM interprets your input and delivers the result is very important. If what you see is just an aggregated result, it's very hard to improve your AI-powered solution. Use platforms like Multinear to see inside the black box of AI.
We invite you to explore the Strawberry Test for yourself. Test your own models, compare results, and see how simple questions can reveal the complex inner workings of modern LLMs.
Try few other inputs:
Test with other words, especially those with similar phonetic or visual similarity to "strawberry," like "raspberry" or "cranberry," to see if LLMs can correctly count 'r's in these contexts as well.
Sentences where the word "strawberry" appears multiple times or in different forms (plural, possessive, etc.), checking if the model can keep track across larger texts. An example: "The strawberry on the table is ripe, but the strawberries in the fridge are not."
Deliberately introduce misspellings like "strawbery" or "strawberrie" to see if the model notices the change and how it impacts the counting.
In the quest for ever-more capable AI, even a humble 🍓 can teach us some interesting lessons.
 | A guest post by
|